The coming years will be defined by intelligent innovation driven by artificial intelligence (AI). As AI continues to advance, it will revolutionize how businesses operate, offering an unparalleled opportunity for organizations to enhance their decision-making, operations, and customer experiences. AI isn’t just a trend—it’s a transformative technology that has already begun reshaping entire industries. In this post, we explore how AI is redefining the future of business and why it’s critical for the C-suite to embrace the shift.
AI’s Inescapable Impact Across Sectors and Industries
In recent years, artificial intelligence has undergone a remarkable transformation, evolving from a niche technology largely confined to research labs and specific industries, to a business critical tool. Organizations worldwide, from small startups to large enterprises, are now leveraging AI to enhance their products and services, streamline operations, optimize supply chains, and automate routine processes and workflows. The ability of AI to process vast amounts of data and identify patterns that would be nearly impossible for humans to detect has made it indispensable in a number of areas including predictive analytics, decision-making, and customer personalization. As a result, companies are increasingly investing in AI-driven solutions to not only reduce operational costs or grow revenue but also gain a competitive edge, build resiliency, and enable data-driven innovation.
AI is becoming integral to transforming traditional business models. For example, industries such as health care are utilizing AI to enhance diagnostic capabilities, streamline administrative processes, and even develop personalized treatment plans. Similarly, in financial services, AI-powered tools are being used to strengthen fraud detection, algorithmic trading, and risk management. In the retail industry is embracing AI for inventory optimization, demand forecasting, and personalized marketing strategies. These broad and diverse applications highlight the pervasive influence of AI in modern business operations.
The global AI market, currently valued at nearly $300 billion, is expected to grow at an exponential rate—$1.8 trillion by 2030. This rapid growth underscores the growing importance of AI as a strategic investment for businesses seeking to stay competitive in an increasingly digital and data-driven world. As AI continues to mature and its capabilities expand, organizations will be required to navigate a complex landscape of ethical considerations, regulatory frameworks, and technological advancements. Nevertheless, the undeniable trajectory of AI’s integration into business operations signifies its status as an essential tool for future success. For example:
AI in Finance is already making waves with its ability to predict market trends and identify financial risks. Companies like Goldman Sachs and JPMorgan Chase have deployed AI systems to enhance trading strategies, automate trading decisions, and improve risk management. AI-driven predictive analytics tools enable financial institutions to gain valuable insights into consumer behavior, fraud detection, and investment strategies. 91% of financial firms have already implemented AI or have concrete plans to do so, highlighting the industry’s rapid embrace of intelligent automation and data-driven decision-making.
AI-powered predictive analytics tools are providing financial institutions with deeper insights into consumer behavior, enabling them to refine customer experiences and develop personalized offerings. AI models are also enhancing investment strategies by analyzing historical data, market sentiment, and macroeconomic indicators to predict future market movements, helping financial firms make smarter, data-driven investment decisions.
AI in Health Care is also taking off. In the U.S., health care is a massive, consequential sector encompassing two major industry groups: (i) health care equipment and services, and (ii) pharmaceuticals, biotechnology, and related life sciences. According to the Congressional Budget Office, “from 2024 to 2033, the CBO forecasts federal subsidies for health care will total $25 trillion, or 8.3% of GDP.” AI is revolutionizing health care by assisting physicians in diagnosing diseases, predicting patient outcomes, personalizing treatments, drug discovery and development, and much more.
A notable advancement in this field is the application of AI in medical image analysis. AI models can swiftly and accurately interpret complex imaging data, aiding in the early detection of conditions such as cancer and cardiovascular diseases. For instance, AI has been utilized to predict heart attacks with up to 90% accuracy, enabling timely interventions.
Moreover, AI-powered wearables are transforming patient monitoring by continuously tracking vital signs and alerting healthcare providers to potential health issues before they become critical. This proactive approach not only enhances patient outcomes but also alleviates the burden on healthcare systems.
These developments underscore AI’s pivotal role in modernizing healthcare, offering tools for more precise diagnoses, personalized treatments, and efficient patient monitoring.
AI in Retail is about adopting AI and intelligent automation to not only enhance personalization but also to create smarter, more efficient operational processes. AI-driven recommendation engines are transforming how brands predict customer preferences and tailor shopping experiences in real time. This level of personalization helps build deeper connections with consumers, driving loyalty and increasing conversion rates. AI is also playing a crucial role in inventory optimization, cost reductions, and demand forecasting, helping retailers minimize out of stock and overstock problems.
The retail industry and the consumer discretionary sector overall are moving toward intelligent automation. A report surveying over 400 retail industry professionals found that over 80% of retailers are actively integrating AI, with a strong focus on enhancing operational efficiency and personalization. Similarly, Fortune 500 retail executives revealed that 90% have initiated generative AI experiments, with 64% conducting pilots and 26% scaling solutions to optimize supply chains and customer interactions. Meanwhile, a 2025 US Retail Industry Outlook report states that AI-powered chatbots increased Black Friday conversion rates by 15%, while 60% of retail buyers credited AI tools with improving demand forecasting and inventory management in 2024. These developments underscore AI’s pivotal role in driving growth, efficiency, and competitive advantage in retail.
AI in Energy is helping optimize grid management, improve renewable energy efficiency, and enhancing energy storage. AI-powered forecasting helps utilities forecast demand, prevent outages, and improve grid reliability. The Electric Power Research Institute (EPRI), alongside Nvidia and Microsoft, recently launched the Open Power AI Consortium to develop AI models that enhance energy management.
In a recent report, the U.S. Depart of Energy (DOE) has outlined “how AI can accelerate the development of a 100% clean electricity system.” This includes the overall improvement to grid planning with the use of generative AI on high-resolution climate data from the National Renewable Energy Laboratory. Another opportunity is the enhancement of grid resilience by using AI to help with diagnosis and response to disruptions. Additionally, there is the opportunity for discovery of new materials pertaining to clean energy technologies.
AI in the energy market is expected to grow from $19 billion last year to $23 billion this year. The size of this market is projected to grow to $51 billion by 2029, at a 20.6% CAGR.
Why AI Has Become a Strategic Priority for C-Level Executives
As AI continues to transform industries across the globe, the question for businesses is no longer if they should adopt AI, but how effectively they can leverage it to stay competitive and relevant. 98% of CEOs say there would be some immediate business benefit from implementing AI and ML. Half of them acknowledge their organization is unprepared to adopt AI/ML due to lack of some or all of the tools, skills, and knowledge necessary to embrace these technologies.
AI’s transformative potential is far-reaching, reshaping operations by driving efficiency, automating complex tasks, and enabling data-driven decision-making at an unprecedented scale. In a recent survey, “78 percent of respondents say their organizations use AI in at least one business function, up from 72 percent in early 2024 and 55 percent a year earlier.” This widespread adoption is being further accelerated by the rapid rise of generative AI, with 71 percent of respondents now stating that their organizations utilize generative AI (in at least one business function). This figure is up from 65 percent earlier in 2024.
For C-suite executives, AI represents a fundamental shift in how businesses operate and compete. 64% of CEOs consider AI a top investment priority, and 76% of them do not envision AI fundamentally impacting job numbers. Leaders who fail to embrace AI run the risk of being outpaced by competitors who harness the power of AI to optimize workflows, enhance customer experiences, improve product development, and drive revenue growth. Organizations are making significant structural changes to harness the full potential of AI, with larger companies often leading the charge. In this rapidly evolving environment, the C-level executives must not only recognize the strategic importance of AI but also take an active role in its implementation.
In a recent cloud and AI business survey, 12% of those surveyed were highlighted as “Top Performers.” These businesses are already ahead of the curve, benefiting from their AI and cloud investments, and defining success. To take better advantage of AI, and generative AI more specifically, 63% of Top Performers are expanding their cloud budgets. The 88% of the companies participating in the survey (those not categorized as Top Performers) are seeing early returns too on their new AI investments. For instance, “41% say they’ve already seen improved customer experience through GenAI while 40% say they’ve already achieved increased productivity. Across each of the 10 categories we asked about, many companies say they’ve already achieved value — but Top Performers stand out because they’re 2X more likely than other companies to have done so.”
Preparing for the AI-Driven Future
Looking forward, AI will become more integrated in every aspect of business operations. AI, machine learning, and automation, including the fast evolving domains of Generative AI and Agentic AI, will continue to expand, creating new opportunities and challenges for executives. The companies that successfully implement AI will unlock new revenue streams, improve operational efficiency, and drive innovation.
The next decade will be defined by intelligent innovation driven by AI. The window of early AI adoption in business is closing fast and many organizations are feeling the competitive squeeze to include AI transformation on their roadmaps. Those who hesitate may find themselves outpaced by competitors who act early.
At Entefy, we are passionate about breakthrough technologies that save people time so they can live and work better. The 24/7 demand for products, services, and personalized experiences is compelling businesses to optimize and, in many cases, reinvent the way they operate to ensure resiliency and growth.
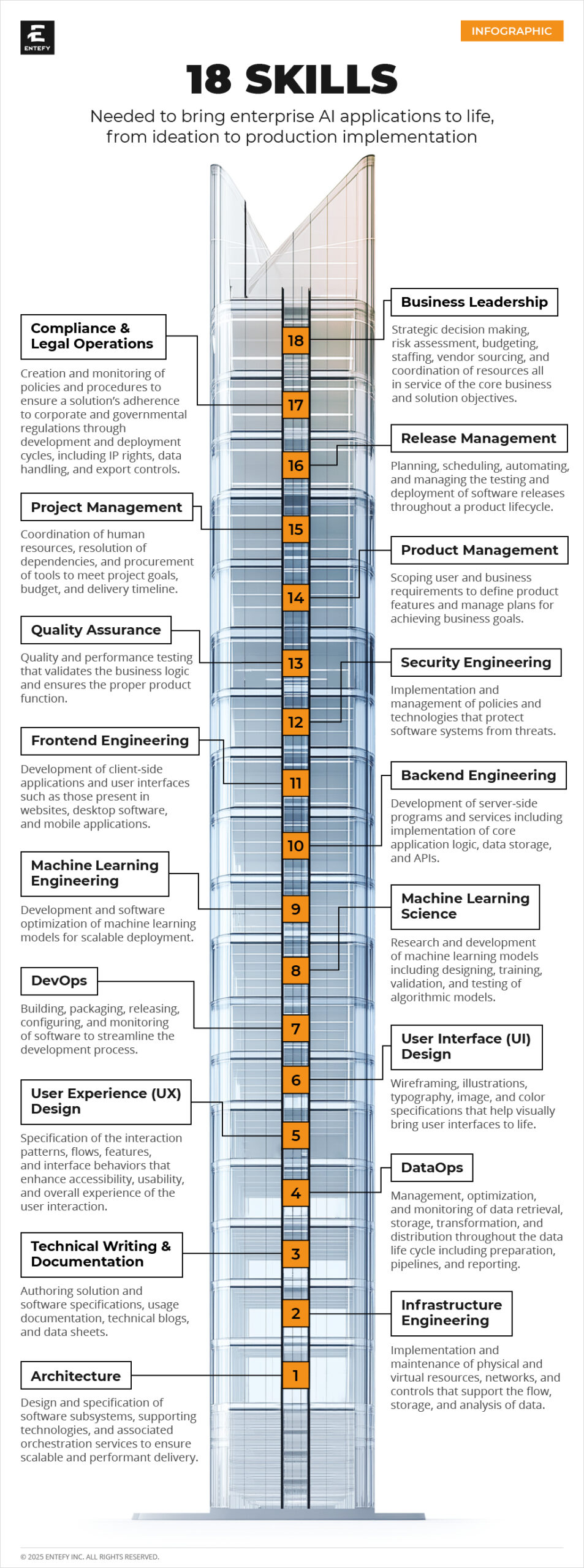
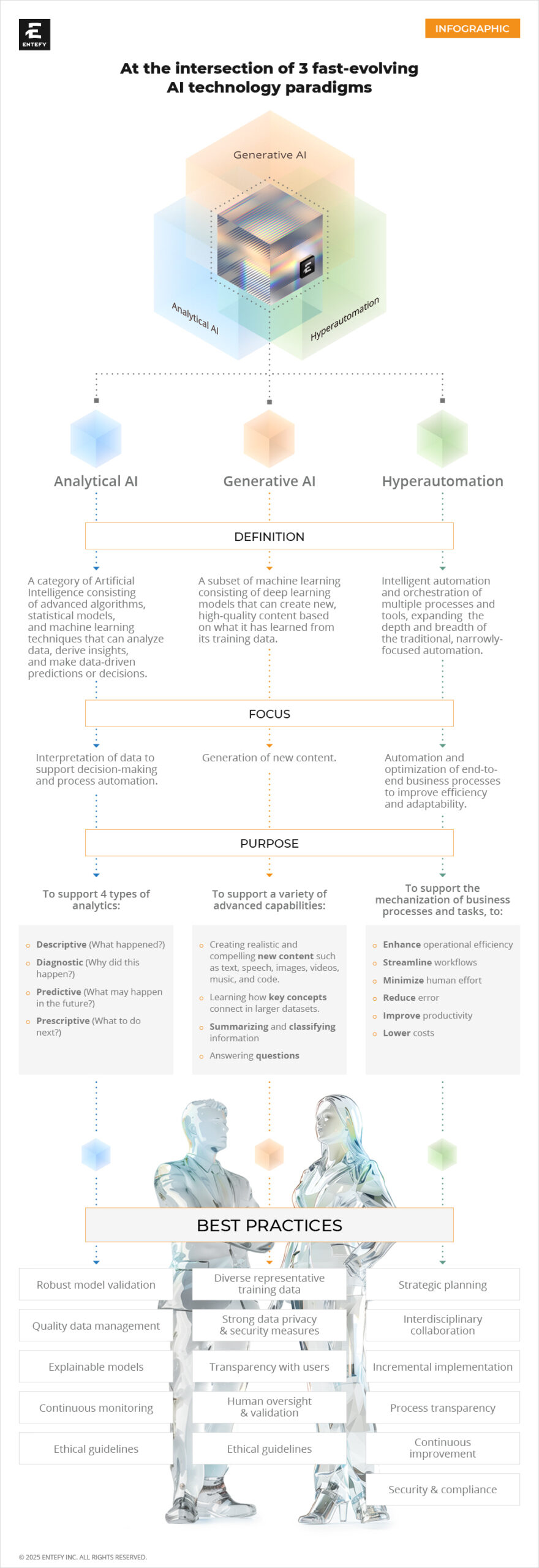
Begin your enterprise AI journey here and be sure to read our previous articles on key AI terms and the 18 skills needed to bring AI applications to life.
ABOUT ENTEFY
Entefy is an enterprise AI software and hyperautomation company. Entefy’s patented, multisensory AI technology delivers on the promise of the intelligent enterprise, at unprecedented speed and scale.
Entefy products and services help organizations transform their legacy systems and business processes—everything from knowledge management to workflows, supply chain logistics, cybersecurity, data privacy, customer engagement, quality assurance, forecasting, and more. Entefy’s customers vary in size from SMEs to large global public companies across multiple industries including financial services, healthcare, retail, and manufacturing.
To leap ahead and future proof your business with Entefy’s breakthrough AI technologies, visit www.entefy.com or contact us at contact@entefy.com.