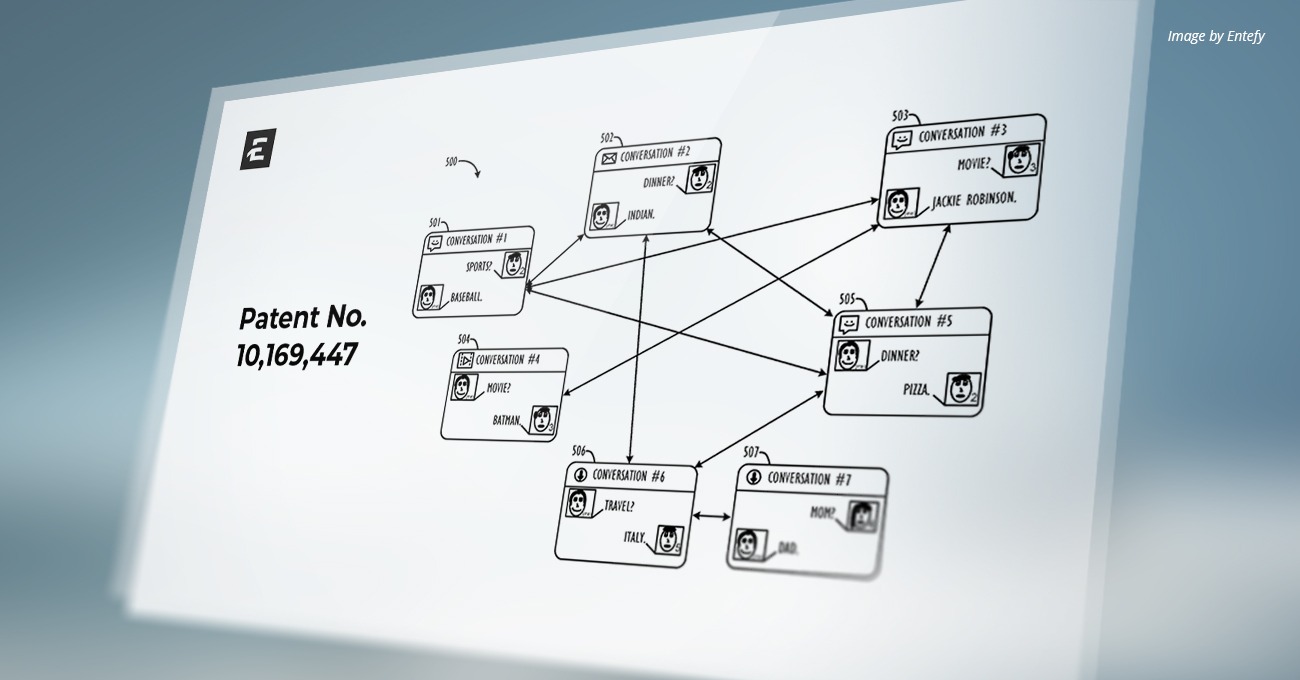
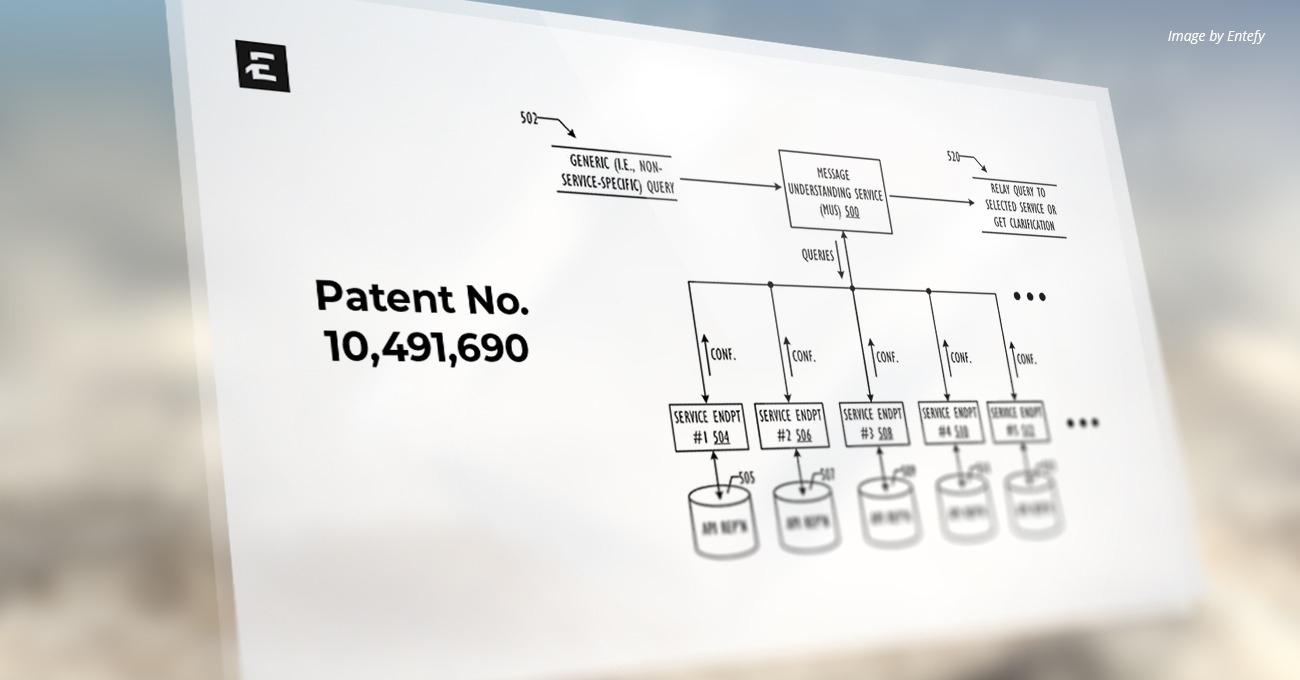
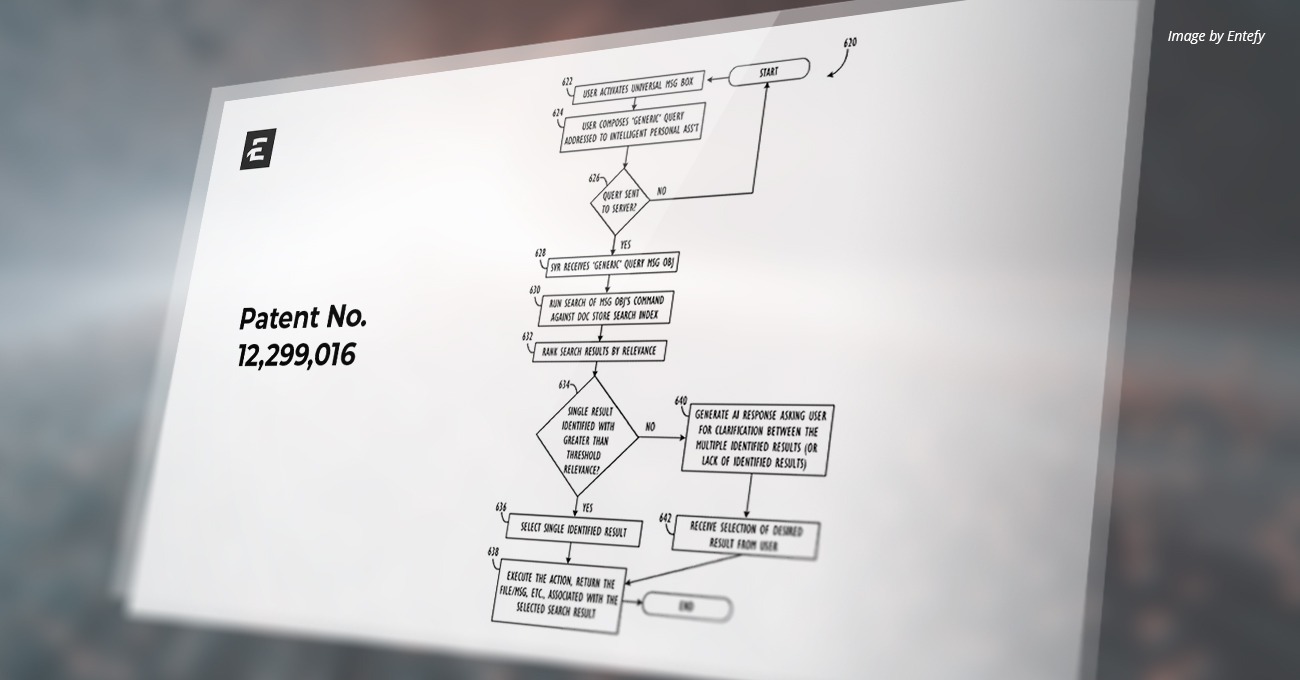
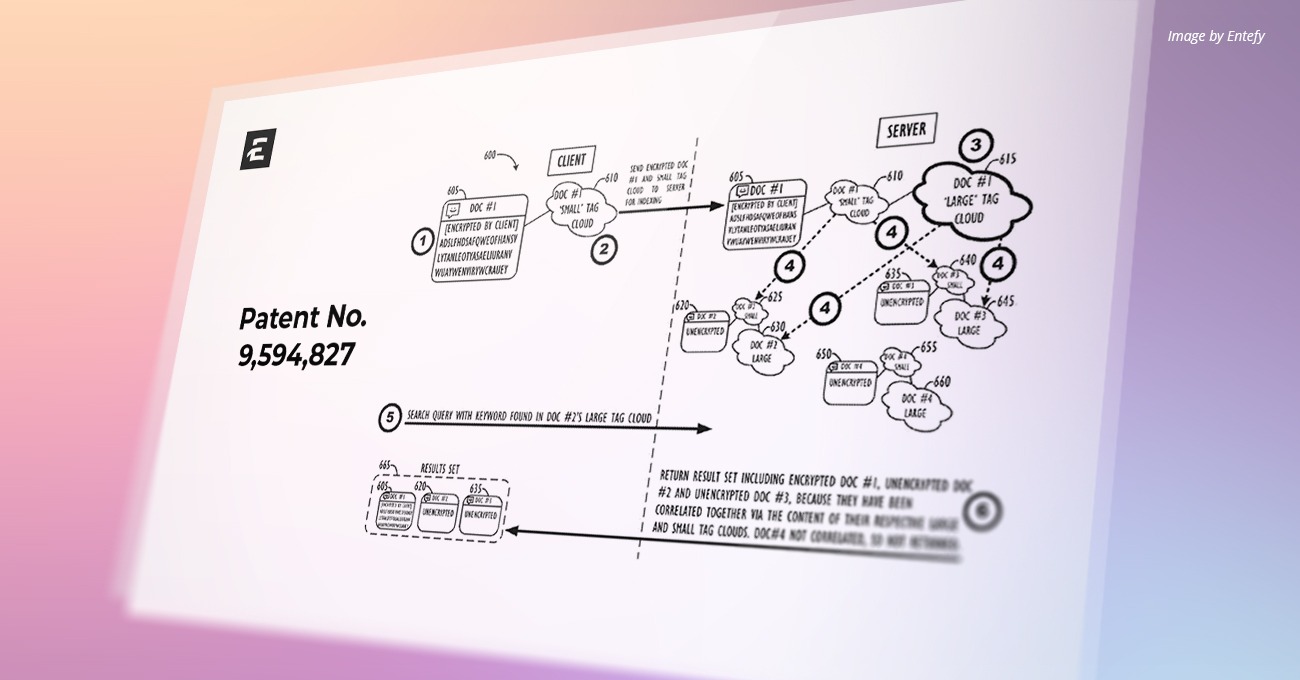
U.S. Patent Number: 10,169,597
Patent Title: System and method of applying adaptive privacy control layers to encoded media file types
Issue Date: May 28, 2019
Inventors: Ghafourifar, et al.
Assignee: Entefy Inc.
Patent Abstract
Disclosed are systems to apply customized permission settings to protect particular regions of a document, and, in particular, documents that are of a ‘lossy’ encoded media file type, e.g., an MPEG video format. The custom access permission settings may be implemented by obfuscating the protected regions of the original file and then embedding “secret,” e.g., hidden and/or encrypted, versions of the obfuscated regions in parts of the data structure of the original file, e.g., in the form of “layers” that are held within video stream containers. The content of the individual encrypted video stream containers may then be decrypted according to each recipient’s permissions and layered on top of the obfuscated regions of the encoded media file before being displayed to the recipient. In some embodiments, additional layers of video may be used to reduce the appearance of aliasing around borders of the protected regions of the encoded media file.
USPTO Technical Field
This disclosure relates generally to systems, methods, and computer readable media for applying user-defined access permission settings to encoded media files in lossy file formats, e.g., MPEG video, which files may then be disseminated over a network and playable by recipients in a wide array of standardized software applications. More particularly, the access permission settings may be implemented by embedding one or more “secret,” e.g., hidden and/or encrypted, information portions in such encoded media file types, e.g., in the form of layers of video information.
Background
The proliferation of personal computing devices in recent years, especially mobile personal computing devices, combined with a growth in the number of widely-used communications formats (e.g., text, voice, video, image) and protocols (e.g., SMTP, IMAP/POP, SMS/MMS, XMPP, etc.) has led to increased concerns regarding the safety and security of documents and messages that are sent over networks. Users desire a system that provides for the setting of custom, e.g., user-defined, access permissions for all or part of a file, including files that have been encoded using lossy compression. A ‘lossy’ file, as used herein, refers to a file (or file format) that is compressed using inexact approximation methods (e.g., partial data discarding methods). As such, lossy compression techniques may be used to reduce data size for storage, handling, and transmitting content. However, because lossy compression reduces a file by permanently discarding certain information (e.g., redundant information), when the file is decompressed, it is not decompressed to 100% of the original. Lossy compression is generally used for multimedia files, e.g., images files, such as JPEG files, video files, such as MPEG files, and/or sound files, such as MP3 files—where a certain amount of information loss will not be detected by most users—and can result in significant gains in file size reduction or performance.
Certain lossy file types may also be described as “single-layered.” For example, in the case of a JPEG image, all the image content information may be stored in the form of a “byte array.” In order to change the appearance (e.g., color) of any pixels in the JPEG image, an editing or modification tool would need to modify or replace the particular information in the byte array corresponding to the region of pixels that are to be changed. Thus, the image data is said to be stored in a “single layer,” as there is no way to alter certain pixel regions in the JPEG image via the layering of new pixel information over the top of the original pixel information. By contrast, more complex image file types that support multiple image layers, e.g., PNG images, offer the ability to store image information in distinct layers which may, e.g., be ‘stacked’ in different orders, individually adjusted for opacity/transparency, or individually moved, rotated, shown, hidden, etc. before composition and display to a viewer. Due to the use of multiple layers, these changes to the image may be made and/or ‘unmade’ without undoing, overwriting, or otherwise degrading the quality of any of the underlying image information in a layer that happens to not be currently shown to the viewer.
Likewise, certain lossy file types for storing encoded multimedia, e.g., the various MPEG video formats, may also provide the ability to support “multi-layered” functionality. For example, through the use of Video Object Planes (VOPs) in certain encoded video files, multiple streams of video data (e.g., each represented in its own VOP) may be rendered simultaneously within the same video frame. A VOP, as used herein, comprises a stream of video data encoding picture information related to a specific region(s) or object(s) of interest that may be interacted with independently before being composited into the final video frames that are rendered for display. As with the PNG image layers discussed above, VOPs within a video frame may be ‘stacked’ on top of the ‘background’ video content in different orders, and can be individually adjusted by a given rendering engine with regard to opacity/transparency, or individually moved, rotated, shown, hidden, etc. before rendering and display to a viewer.
In some embodiments described herein, VOPs (or other parts of the video’s file structure), which are generically referred to herein as “stream containers,” may be used to hold isolated video bitstreams that an authorized encoded media viewing application may interpret and/or use in ways other than simple playback, as will be discussed in further detail below. For example, according to some embodiments described herein, the video bitstreams held in one or more of the stream containers packaged in the video’s file structure may need to be decrypted before being played back. In still other embodiments, the view of the video bitstreams held in one or more of the stream containers packaged in the video’s file structure may be adjusted before being rendered and displayed to a viewer, e.g., by adjusting the dimensions of the video bitstream that are actually made viewable to the viewer.
Lossy file types may also contain multiple “header,” or metadata, properties. These header properties may be used to store alternate contents such as metadata or other random information. Some lossy file types may also allow for the storage of multiple “layers” of media information within the same file, or even full encoding of other files or portions of files within the same file (e.g., in the case of VOPs within an MPEG file), such as in the embodiments described herein. Such a system would allow customized privacy settings to be specified for different recipients, e.g., recipients at various levels of social distance from the user sending the document or message (e.g., public, private, followers, groups, Level-1 contacts, Level-2 contacts, Level-3 contacts, etc.). Such a system may also allow the user to apply customized privacy settings and encryption keys differently to particular parts of a lossy file, e.g., making one or more parts of the lossy file available only to a first class of users, or by making other parts of the lossy file available to the first class of users and a second class of users, all while preventing access to parts of lossy file by users who do not have the requisite access privileges.
Thus, a system for providing access permission setting through Adaptive Privacy Controls (APC) is described herein. APC, as used herein, will refer to a user-controllable or system-generated, intelligent privacy system that can limit viewing, editing, and re-sharing privileges for lossy files, for example, image files and other multimedia files that include a lossy compression (including encoded multimedia file types), wherein changes made to the content of such ‘lossy’ files may not be reliably reversed or dynamically changed—as would be necessary according to prior art techniques attempting to implement the kinds of fine-grained access permission setting methods disclosed herein. Other embodiments of APC systems will, of course, be able to handle the setting of access permissions for recipients of lossless file formats, as well. In summary, APC systems, as used herein, allow users to share whatever information they want with whomever they want, while keeping others from accessing the same information, e.g., via hiding and/or encryption processes that can be initiated by user command or via system intelligence, even on lossy file types, and even when more than one region (including overlapping regions) in an encoded multimedia file have been selected by a user for APC-style protection. APC access permission settings may be applied to individuals, pre-defined groups, and/or ad-hoc groups. Customized encryption keys may further be applied to particular parties or groups of parties to enhance the security of the permission settings.
APC may be used to apply privacy settings to only particular portions of a lossy file, for example, a particular portion of a JPEG image or a frame (or series of frames) from an MPEG video. For example, User A may be a family member who may be authorized to see an entire JPEG image or MPEG video, but User B and other users may be mere acquaintances, who are only authorized to see a redacted portion or portions of the JPEG image or MPEG video. For example, the entire JPEG image or MPEG video file would be viewable to User A, but only a redacted portion or portions (e.g., everything but the face of the subject(s) in the image) would be available to the User B and other users when viewing the JPEG image or MPEG video file in an authorized viewing application.
According to some embodiments disclosed herein, a standard, i.e., “unauthorized,” viewing application, e.g. an image viewer or video player, would also be able to open the redacted version of the JPEG image or MPEG video file; it simply may not “know” where to look within the multimedia file’s structure for the “true” content from the redacted portion or portions of the JPEG image or MPEG video file. According to still other embodiments, even if an unauthorized viewing application were able to find the “true” content from the redacted portion or portions “hidden” within the file structure of the JPEG image or MPEG video (e.g., in the case of VOPs), the redacted portion or portions may be encrypted, and the unauthorized viewing application would not possess the necessary decryption keys to decrypt the encrypted redacted portion or portions. Moreover, the unauthorized viewing application also would not know where to “place” the encrypted portion or portions back within the image to reconstruct the original, i.e., unredacted, JPEG image or MPEG video in a seamless fashion.
Thus, according to some embodiments, the network-based, user-defined, APC controls for lossy file types or files (e.g., encoded media file types, such as MPEG) may include access permission systems, methods, and computer readable media that provide a seamless, intuitive user interface (e.g., using touch gestures or mouse input) allowing a user to: “block out” particular regions or areas of interest in a lossy file; hide (and optionally encrypt) such “blocked out” regions within parts the lossy file’s data structure; and then send the lossy file to particular recipients or groups of recipients with customized access permission settings, which settings may be specified on a per-recipient or per-group basis, and that either allow or do not allow a given recipient to locate the protected regions (if hidden) and decrypt such protected regions (if encrypted), so that the original lossy file may be reconstructed by the recipient.
Read the full patent here.
ABOUT ENTEFY
Entefy is an enterprise AI software company. Entefy’s patented, multisensory AI technology delivers on the promise of the intelligent enterprise, at unprecedented speed and scale.
Entefy products and services help organizations transform their legacy systems and business processes—everything from knowledge management to workflows, supply chain logistics, cybersecurity, data privacy, customer engagement, quality assurance, forecasting, and more. Entefy’s customers vary in size from SMEs to large global public companies across multiple industries including financial services, healthcare, retail, and manufacturing.
To leap ahead and future proof your business with Entefy’s breakthrough AI technologies, visit www.entefy.com or contact us at contact@entefy.com.