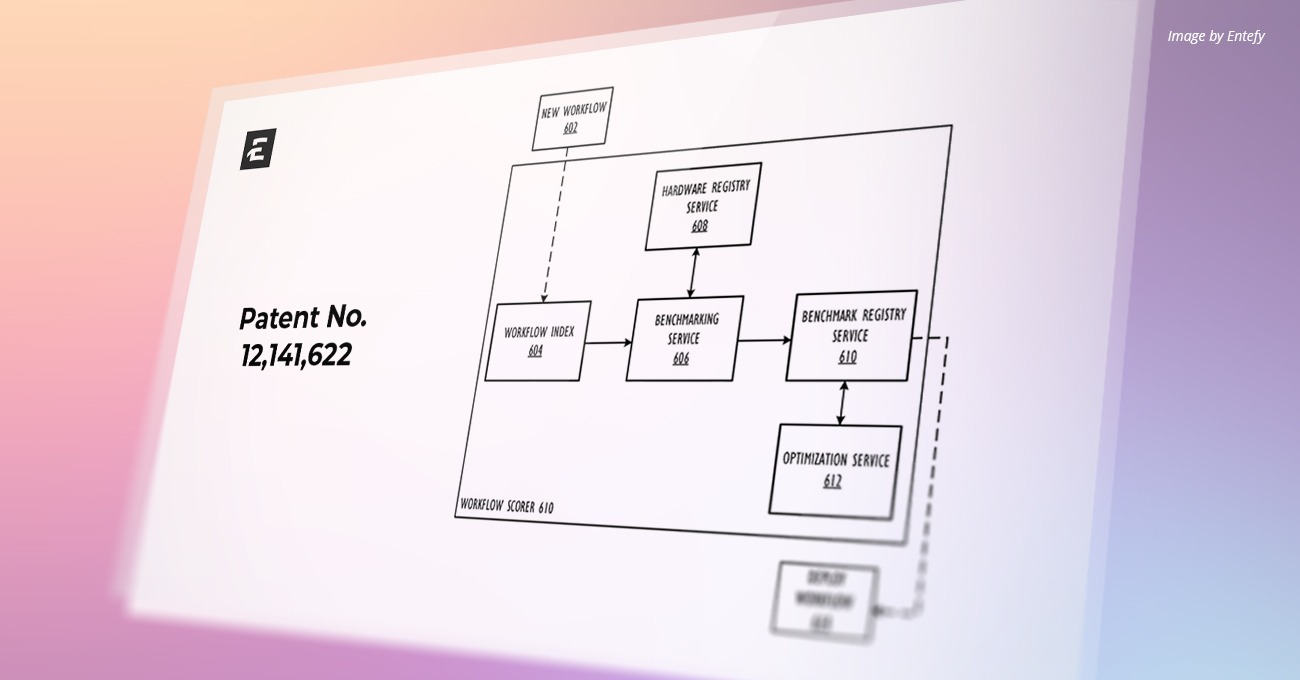
U.S. Patent Number: 12,141,622
Patent Title: Dynamic distribution of a workload processing pipeline on a computing infrastructure
Issue Date: November 12, 2024
Inventors: Alston Ghafourifar
Assignee: Entefy Inc.
Patent Abstract
Disclosed are systems, methods, and computer readable media for automatically assessing and allocating virtualized resources (such as central processing unit (CPU) and graphics processing unit (GPU) resources). In some embodiments, this method involves a computing infrastructure receiving a request to perform a workload, determining one or more workflows for performing the workload, selecting a virtualized resource, from a plurality of virtualized resources, wherein the virtualized resource is associated with a hardware configuration, and wherein selecting the virtualized resources is based on a suitability score determined based on benchmark scores of the one or more workflows on the hardware configuration, scheduling performance of at least part of the workload on the selected virtualized resource, and outputting results of the at least part of the workload.
USPTO Technical Field
This disclosure relates generally to apparatuses, methods, and computer readable media for predicting and allocating computing resources for workloads.
Background
Modern computing infrastructures allow computational resources to be shared through one or more networks, such as the internet. For example, a cloud computing infrastructure may enable users, such as individuals and/or organizations, to access shared pools of computing resources, such as servers, both virtual and real, storage devices, networks, applications, and/or other computing based services. Remote services allow users to access computing resources on demand remotely in order to perform a variety computing functions. These functions may include computing data. For example, cloud computing may provide flexible access to computing resources without accruing up-front costs, such as purchasing computing devices, networking equipment, etc. and investing time in establishing a private network infrastructure. Utilizing remote computing resources, users are able to focus on their core functionality rather than optimizing data center operations.
With today’s communications networks, examples of cloud computing services a user may access includes software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS) technologies. SaaS is a delivery model that provides software as a service rather than an end product, while PaaS acts an extension of SaaS that goes beyond providing software services by offering customizability and expandability features to meet a user’s needs. Another example of cloud computing service includes infrastructure as a service (IaaS), where APIs are provided to access various computing resources, such as raw block storage, file or object level storage, virtual local area networks, firewalls, load balancers, etc. Service systems may handle requests for various resources using virtualized resources (VRs). VRs allows for hardware resources, such as servers, to be pooled for use by the service systems. These VRs may be configured using pools of hypervisors for virtual machines (VMs) or through containerization.
Containerization, or containers, are generally a logical packaging mechanism of resources for running an application which are abstracted out from the environment in which they are actually run. Multiple containers generally may be run directly on top of a host OS kernel and each container generally contains the resources, such as storage, memory, and APIs needed to run a particular application the container is set up to run. In certain cases, containers may be resized by adding or removing resources dynamically to account for workloads or a generic set of resources may be provided to handle different applications. As containers are created on and managed by a host system at a low level, they can be spawned very quickly. Containers may be configured to allow access to host hardware, such as central processing units (CPUs) or graphics processing units (GPUs), for example, through low-level APIs included with the container. Generally, containers may be run in any suitable host system and may be migrated from one host system to another as hardware and software compatibility is handled by the host and container layers. This allows for grouping containers to optimize use of the underlying host system. A host controller may also be provided to optimize distribution of containers across hosts.
Modern CPUs may be configured to help distribute CPU processing load across multiple processing cores, therefore allowing multiple computing tasks to execute simultaneously and reduce overall real or perceived processing time. For example, many CPUs include multiple independent and asynchronous cores, each capable of handling different tasks simultaneously. Generally, GPUs, while having multiple cores, can be limited in their ability to handle multiple different tasks simultaneously. A typical GPU can be characterized as a processor which can handle a Single Instruction stream with Multiple Data streams (SIMD) whereas a typical multi-core CPU can be characterized as a processor which can handle Multiple Instruction streams with Multiple Data streams (MIMD). A multi-core CPU or a cluster of multiple CPUs can also be characterized as parallelized SIMD processor(s), thereby in effect simulating a MIMD architecture.
A SIMD architecture is generally optimized to perform processing operations for simultaneous execution of the same computing instruction on multiple pieces of data, each processed using a different core. A MIMD architecture is generally optimized to perform processing operations which requires simultaneous execution of different computing instructions on multiple pieces of data, regardless of whether executing processes are synchronized. As such, SIMD processors, such as GPUs, typically perform well with discrete, highly parallel, computational tasks spread across as many of the GPU cores as possible and making use of a single instruction stream. Many GPUs have specific hardware and firmware limitations in place to limit the ability for the GPU cores to be separated, or otherwise virtualized, thereby reinforcing the SIMD architecture paradigm. CPUs typically have little or no such limitation, thereby making the process of dividing GPU processing time across multiple tasks difficult as compared to CPUs. Rather than attempting this, IaaS providers with GPU resources may need to provide more physical GPUs to handle GPU processing requests and possibly even dedicated GPUs for certain processes, for example, artificial intelligence (AI) workloads, even if the actual computational capacity of that infrastructure far out-strips the GPU compute demand, leading to inflated capital and operating costs associated with offering GPU resources in an IaaS, PaaS, SaaS, or other product or cloud infrastructure offering.
In the case of GPU-heavy workloads such as those demanded by certain AI-enabled offerings, not all AI workloads are the same and hardware optimal for running one AI workload may not be rightly-sized for another AI workload.
Virtualization techniques have emerged throughout the past decades to optimize the utilization of hardware resources such as CPUs by efficiently allowing computing tasks to be spread across multiple cores, CPUs, clusters, etc. However, such virtualization is generally not available or non-performant for GPUs and this can lead to higher operating costs and increased application or platform latency. What is needed is a technique for appropriately scaling a workflow pipeline to handle high-density processing operations (such as AI operations) which require frequent utilization of GPUs during processing.
Read the full patent here.
ABOUT ENTEFY
Entefy is an enterprise AI software company. Entefy’s patented, multisensory AI technology delivers on the promise of the intelligent enterprise, at unprecedented speed and scale.
Entefy products and services help organizations transform their legacy systems and business processes—everything from knowledge management to workflows, supply chain logistics, cybersecurity, data privacy, customer engagement, quality assurance, forecasting, and more. Entefy’s customers vary in size from SMEs to large global public companies across multiple industries including financial services, healthcare, retail, and manufacturing.
To leap ahead and future proof your business with Entefy’s breakthrough AI technologies, visit www.entefy.com or contact us at contact@entefy.com.