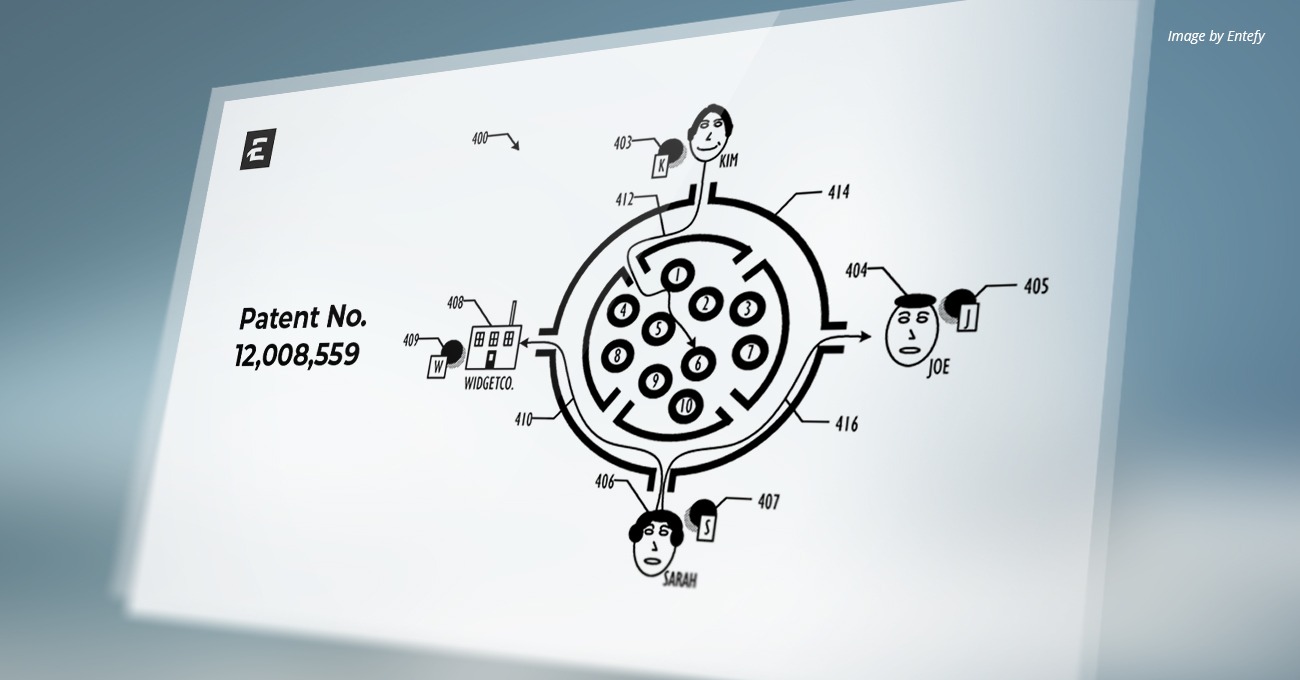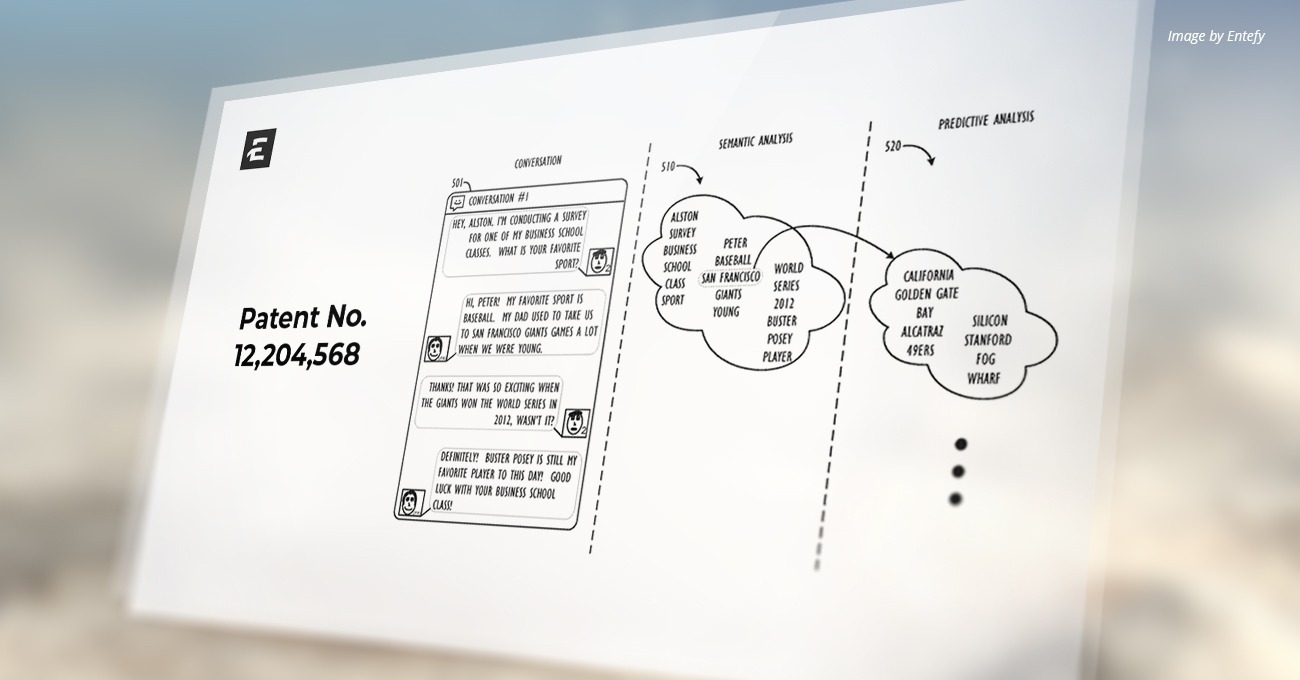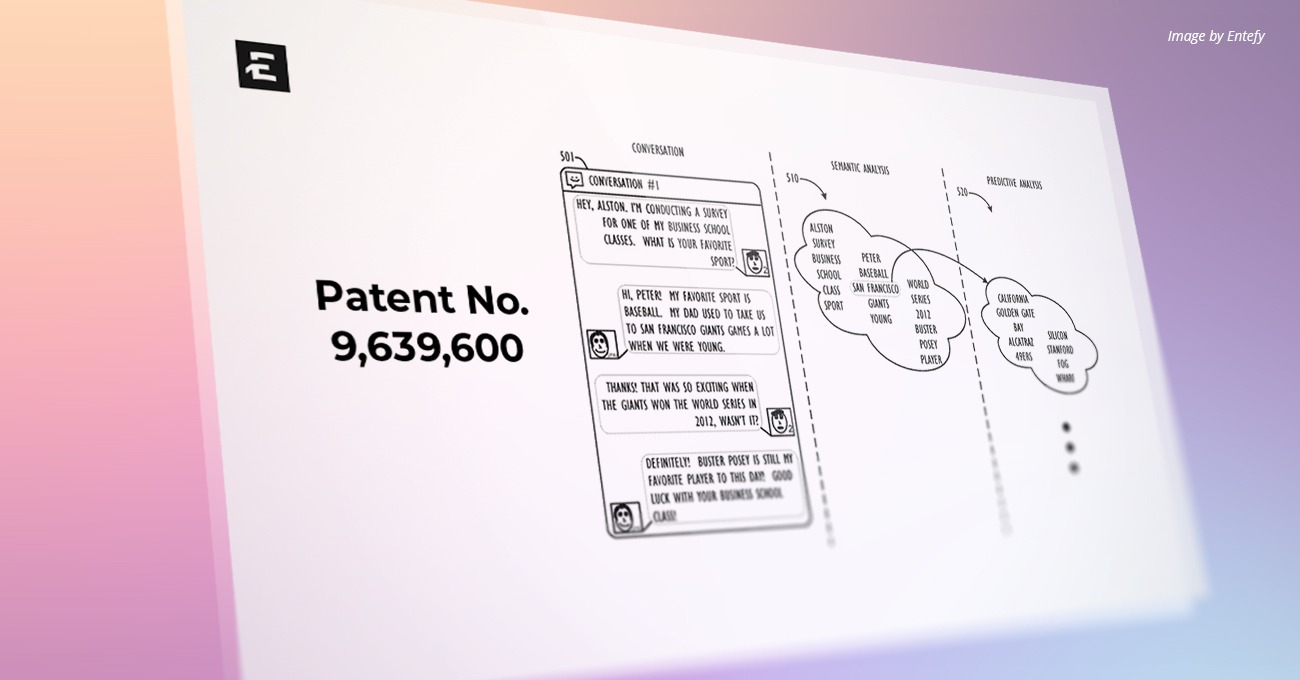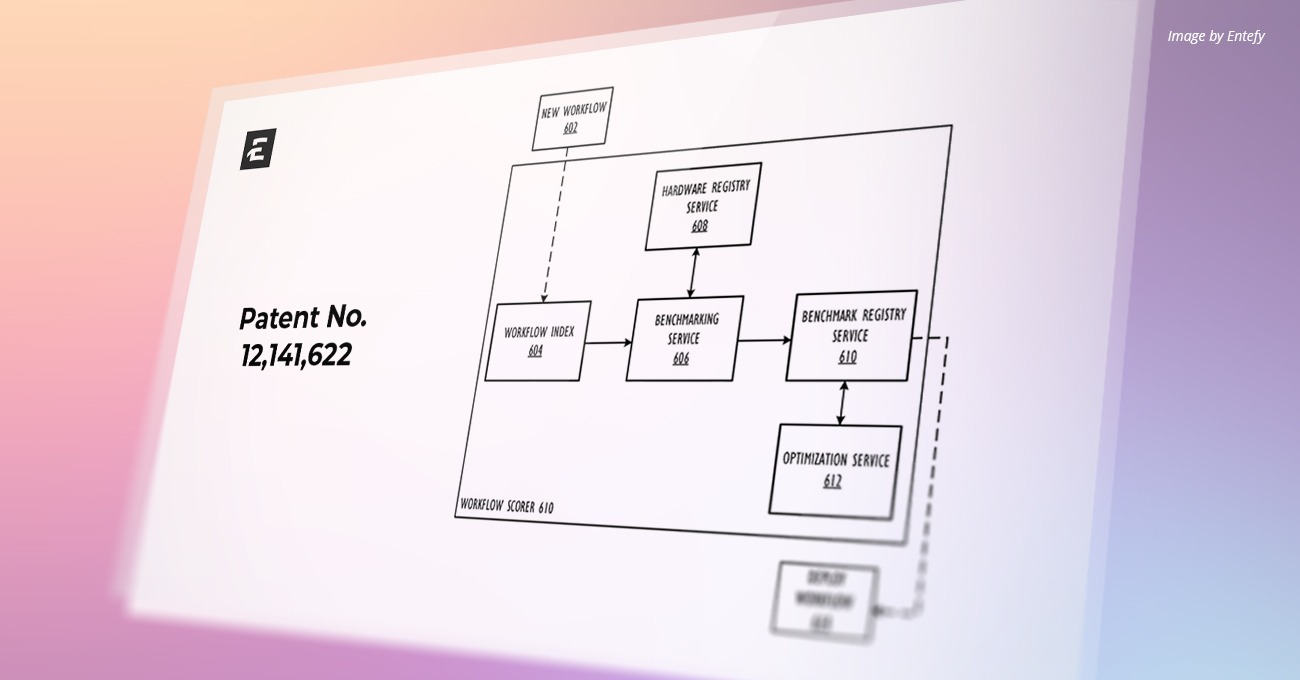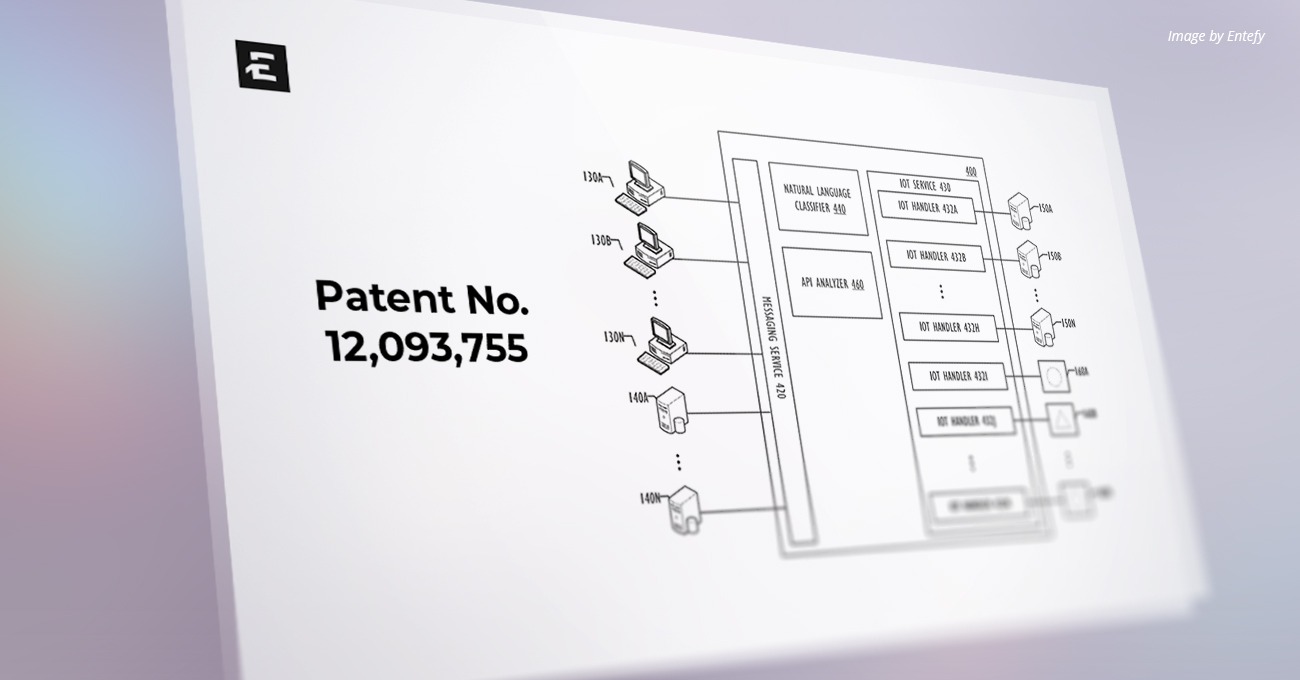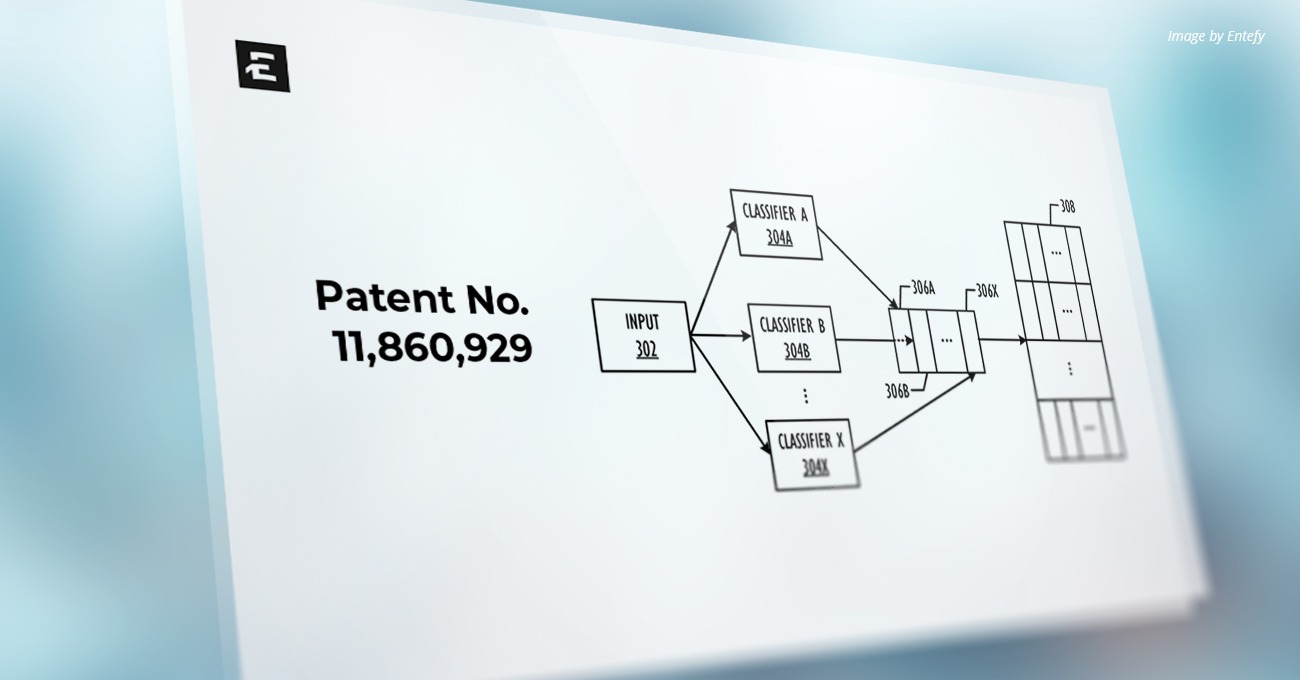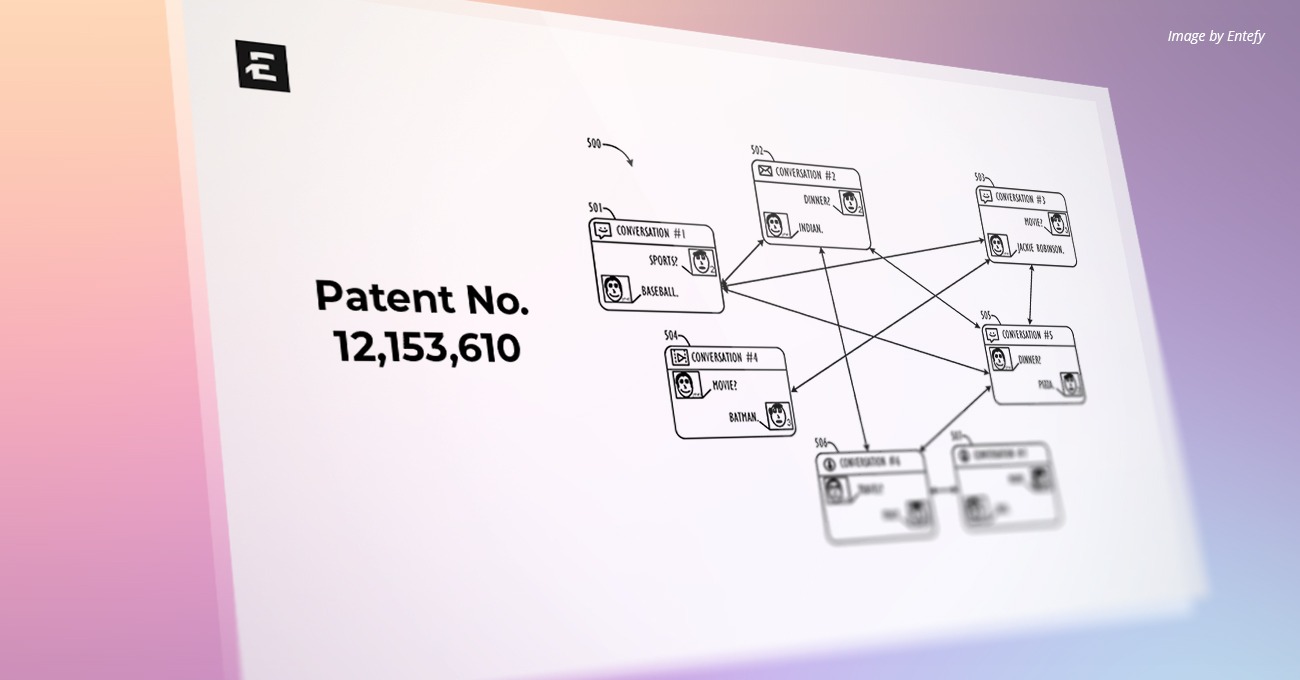
U.S. Patent Number: 12,153,610
Patent Title: System and method of information retrieval from encrypted data files through a context-aware metadata AI engine
Issue Date: November 26, 2024
Inventors: Ghafourifar, et al.
Assignee: Entefy Inc.
Patent Abstract
This disclosure relates to personalized and dynamic server-side searching techniques for encrypted data. Current so-called ‘zero-knowledge’ privacy systems (i.e., systems where the server has ‘zero-knowledge’ about the client data that it is storing) utilize servers that hold encrypted data without the decryption keys necessary to decrypt, index, and/or re-encrypt the data. As such, the servers are not able to perform any kind of meaningful server-side search process, as it would require access to the underlying decrypted data. Therefore, such prior art ‘zero-knowledge’ privacy systems provide a limited ability for a user to search through a large dataset of encrypted documents to find critical information. Disclosed herein are communications systems that offer the increased security and privacy of client-side encryption to content owners, while still providing for highly relevant server-side search-based results via the use of content correlation, predictive analysis, and augmented semantic tag clouds for the indexing of encrypted data.
USPTO Technical Field
This disclosure relates generally to systems, methods, and computer readable media for performing highly relevant, dynamic, server-side searching on encrypted data that the server does not have the ability to decrypt.
Background
The proliferation of personal computing devices in recent years, especially mobile personal computing devices, combined with a growth in the number of widely-used communications formats (e.g., text, voice, video, image) and protocols (e.g., SMTP, IMAP/POP, SMS/MMS. XMPP, etc.) has led to a communications experience that many users find fragmented and difficult to search for relevant information in. Users desire a system that will provide for ease of message threading by “stitching” together related communications and documents across multiple formats and protocols-all seamlessly from the user’s perspective. Such stitching together of communications and documents across multiple formats and protocols may occur, e.g., by: 1) direct user action in a centralized communications application (e.g., by a user clicking ‘Reply’ on a particular message); 2) using semantic matching (or other search-style message association techniques); 3) element-matching (e.g., matching on subject lines or senders/recipients/similar quoted text, etc.); and/or 4) “state-matching” (e.g., associating messages if they are specifically tagged as being related to another message, sender, etc. by a third-party service, e.g., a webmail provider or Instant Messaging (IM) service). These techniques may be employed in order to provide a more relevant “search-based threading” experience for users.
With current communications technologies, conversations remain “siloed” within particular communication formats or protocols, leading to users being unable to search uniformly across multiple communications in multiple formats or protocols and across multiple applications and across multiple other computing devices from their computing devices to find relevant communications (or even communications that a messaging system may predict to be relevant), often resulting in inefficient communication workflows—and even lost business or personal opportunities. For example, a conversation between two people may begin over text messages (e.g., SMS) and then transition to email. When such a transition happens, the entire conversation can no longer be tracked, reviewed, searched, or archived by a single source since it had ‘crossed over’ protocols. For example, if the user ran a search on their email search system for a particular topic that had come up only in the user’s SMS conversations, even when pertaining to the same subject manner and “conversation,” such a search may not turn up optimally relevant results.
Users also desire a communications system with increased security and privacy with respect to their communications and documents, for example, systems wherein highly relevant search-based results may still be provided to the user by the system-even without the system actually having the ability to decrypt and/or otherwise have access to the underlying content of the user’s encrypted communications and documents. However, current so-called ‘zero-knowledge’ privacy systems (i.e., systems where the server has ‘zero-knowledge’ about the data that it is storing) utilize servers that hold encrypted data without the decryption keys necessary to decrypt, index, and/or re-encrypt the data. As such, this disallows any sort of meaningful server-side search process, which would require access to the underlying data (e.g., in order for the data to be indexed) to be performed, such that the encrypted data could be returned in viable query result sets. Therefore, such prior art ‘zero-knowledge’ systems provide a limited ability for a user to search through a large dataset of encrypted documents to find critical information.
It should be noted that attempts (both practical and theoretical) have been made to design proper ‘zero-knowledge’ databases and systems that can support complex query operations on fully encrypted data. Such approaches include, among others, homomorphic encryption techniques which have been used to support numerical calculations and other simple aggregations, as well as somewhat accurate retrieval of private information. However, no solution currently known to the inventors enables a system or database to perform complex operations on fully-encrypted data, such as index creation for the purpose of advanced search queries. Thus, the systems and methods disclosed herein aim to provide a user with the ability to leverage truly private, advanced server-side search capabilities from any connected client interface without relying on a ‘trusted’ server authority to authenticate identity or store the necessary key(s) to decrypt the content at any time.
Read the full patent here.
ABOUT ENTEFY
Entefy is an enterprise AI software company. Entefy’s patented, multisensory AI technology delivers on the promise of the intelligent enterprise, at unprecedented speed and scale.
Entefy products and services help organizations transform their legacy systems and business processes—everything from knowledge management to workflows, supply chain logistics, cybersecurity, data privacy, customer engagement, quality assurance, forecasting, and more. Entefy’s customers vary in size from SMEs to large global public companies across multiple industries including financial services, healthcare, retail, and manufacturing.
To leap ahead and future proof your business with Entefy’s breakthrough AI technologies, visit www.entefy.com or contact us at contact@entefy.com.